当网格搜索效率低下时,我们可以考虑使用迭代搜索法。
迭代搜索可以预测下一步要测试的超参数集。
迭代搜索有两种方式:
贝叶斯优化
使用SVM模型(?sec-Neural-Networks-and-SV ) 展示贝叶斯优化的过程。
模型建立和初始网格设置
SVM模型需要调优的两个超参数为惩罚系数cost和径向基核函数的参数$\sigma$。
SVM模型需要对预测变量进行中心化和缩放。
迭代搜索过程前,需要进行一些重抽样的性能统计数据,即需要一个初始的网格重抽样作为起始点,以获得初始的性能统计数据。
library ( tidymodels ) tidymodels_prefer ( ) svm_spec <- svm_rbf ( cost = tune ( ) ,
rbf_sigma = tune ( )
) %>% set_engine ( "kernlab" ) %>%
set_mode ( "classification" )
svm_recipe <- recipe ( class ~ . ,
data = cells
) %>% # Yeo-Johnson transformation: 减少随机变量的变异性,使其形态向正态分布靠近。
# Yeo-Jonhson transformation可以应用于包含0值和负值的样本。
step_YeoJohnson ( all_numeric_predictors ( ) ) %>%
step_normalize ( all_numeric_predictors ( ) )
svm_wflow <- workflow ( ) %>% add_model ( svm_spec ) %>%
add_recipe ( svm_recipe )
# 查看超参数默认范围 cost ( ) rbf_sigma ( ) # 提取超参数集并修改rbf_sigma的范围 svm_param <- svm_wflow %>%
extract_parameter_set_dials ( ) %>%
update ( rbf_sigma = rbf_sigma ( c ( - 7 , - 1 ) ) )
# 创建初始网格 set.seed ( 1401 ) start_grid <- svm_param %>%
update (
cost = cost ( c ( - 6 , 1 ) ) ,
rbf_sigma = rbf_sigma ( c ( - 6 , - 4 ) )
) %>%
grid_regular ( levels = 2 )
## 对初始网格进行重抽样计算 set.seed ( 1402 ) svm_initial <- svm_wflow %>%
tune_grid (
resamples = cell_folds ,
grid = start_grid ,
metrics = roc_res
)
maximum number of iterations reached 0.01985804 0.01947119maximum number of iterations reached 0.01951676 0.01912962maximum number of iterations reached 0.01929118 0.01895888maximum number of iterations reached 0.01938124 0.01905198maximum number of iterations reached 0.01967913 0.01930207maximum number of iterations reached 0.02022452 0.01983573maximum number of iterations reached 0.0194954 0.01916201maximum number of iterations reached 0.0204274 0.01999696maximum number of iterations reached 0.01870142 0.01838042maximum number of iterations reached 0.01978898 0.01941516
# Tuning results
# 10-fold cross-validation
# A tibble: 10 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [1817/202]> Fold01 <tibble [4 × 6]> <tibble [0 × 4]>
2 <split [1817/202]> Fold02 <tibble [4 × 6]> <tibble [0 × 4]>
3 <split [1817/202]> Fold03 <tibble [4 × 6]> <tibble [0 × 4]>
4 <split [1817/202]> Fold04 <tibble [4 × 6]> <tibble [0 × 4]>
5 <split [1817/202]> Fold05 <tibble [4 × 6]> <tibble [0 × 4]>
6 <split [1817/202]> Fold06 <tibble [4 × 6]> <tibble [0 × 4]>
7 <split [1817/202]> Fold07 <tibble [4 × 6]> <tibble [0 × 4]>
8 <split [1817/202]> Fold08 <tibble [4 × 6]> <tibble [0 × 4]>
9 <split [1817/202]> Fold09 <tibble [4 × 6]> <tibble [0 × 4]>
10 <split [1818/201]> Fold10 <tibble [4 × 6]> <tibble [0 × 4]>
## 提取性能指标 collect_metrics ( svm_initial )
# A tibble: 4 × 8
cost rbf_sigma .metric .estimator mean n std_err .config
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0156 0.000001 roc_auc binary 0.864 10 0.00864 pre0_mod1_post0
2 0.0156 0.0001 roc_auc binary 0.863 10 0.00862 pre0_mod2_post0
3 2 0.000001 roc_auc binary 0.863 10 0.00867 pre0_mod3_post0
4 2 0.0001 roc_auc binary 0.866 10 0.00855 pre0_mod4_post0
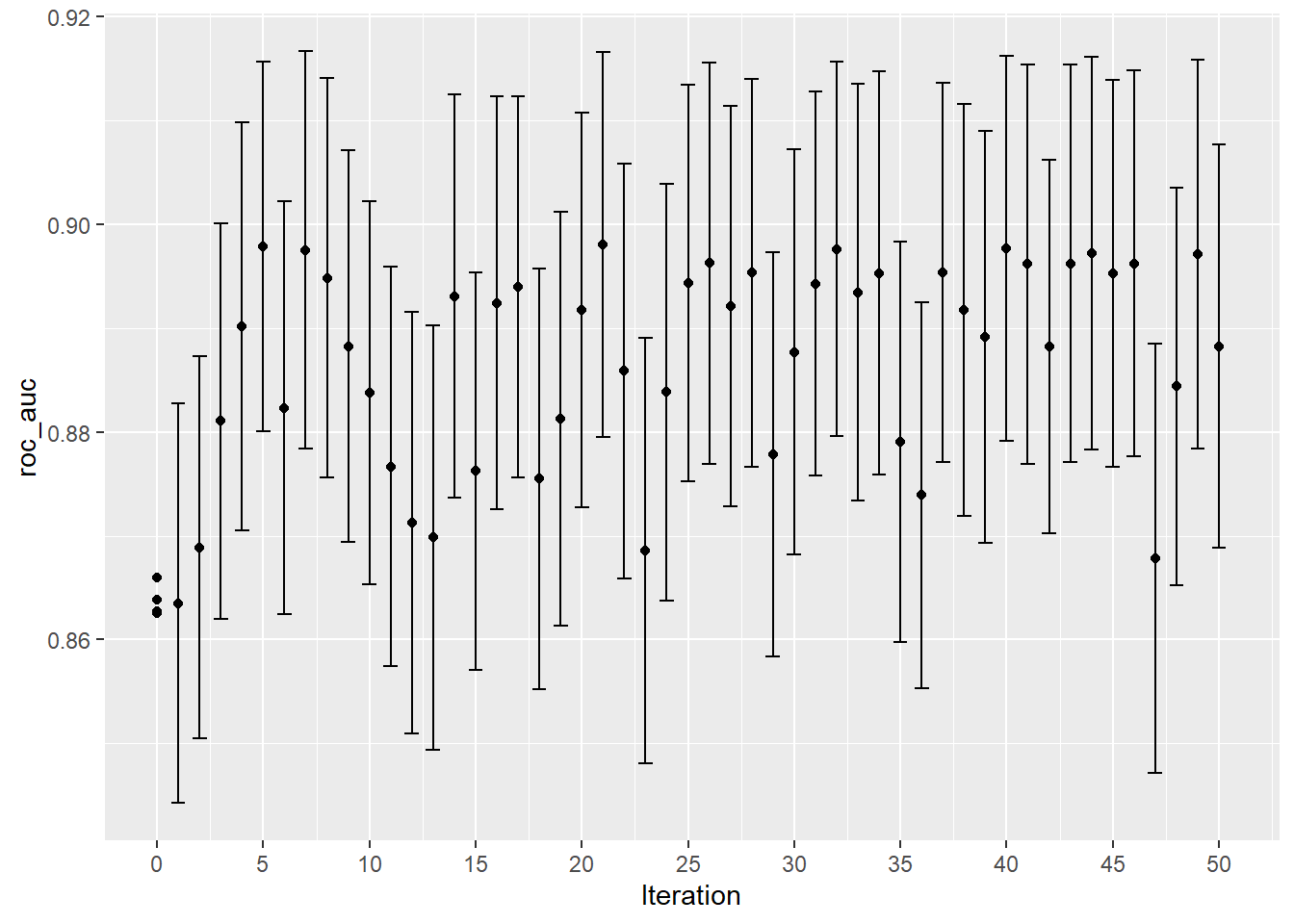
可以看出,初始网格的评估结果非常相近,没有哪个超参数组合明显好于其他组合。
这个结果作为初始值继续用作迭代搜索的起始点。
贝叶斯优化
贝叶斯优化技术的基本思想是:使用初始网格重抽样结果创建一个预测模型用来探索尚未被评估的超参数组合,并根据该模型的预测结果继续进行抽样评估,直到找到对模型性能不会发生改变的最优超参数组合为止。
贝叶斯优化最常用的技术之一为高斯过程模型:具体可参看知乎文章:快速入门高斯过程(Gaussian process)回归预测 。
在高斯过程拟合当前数据后,采用 采集函数(acquisition function) 选择下一个超参数点。
最常用的采集函数为 期望改进(expected improvement) ,即基于当前模型预测的最值,利用贝叶斯推断的结果计算每个参数点的期望改进值;选择期望改进值最大的候选参数点作为下一个采样点。
tidymodels中提供了tune_bayes() tune_bayes() tune_grid() resampling、metrics等,此外,还有包括了几个额外的参数:
iter:迭代次数。
initial:初始网格,可以是一个正整数(指定空间填充的网格大小)或由tune_grid() 如果初始网格设置了随机种子数,则空间填充设计是比规则网格更好的选择。
objective:使用的采集函数,默认使用exp_improve() conf_bond()`可供选择。
param_info:超参数集对象,指定超参数的范围和转换方式。
control:使用control_bayes()
no_improve:整数对象,在指定次数迭代后仍然没有改进,则停止迭代。
uncertain:整数对象,在指定次数迭代后仍然没有改进,则会进行一个不确定性采样。
verbose:逻辑值,是否显示迭代过程。
tidymodels中默认使用期望改进。其他的采集函数还有UCB(upper confidence bond)、PI(probability of improvement)函数等
bayes_control <- control_bayes ( verbose = TRUE ) set.seed ( 1403 ) svm_bayes_opt <- svm_wflow %>%
tune_bayes (
resamples = cell_folds ,
metrics = roc_res ,
initial = svm_initial ,
param_info = svm_param ,
objective = "exp_improve" , # 默认采集函数
iter = 25 ,
control = bayes_control
)
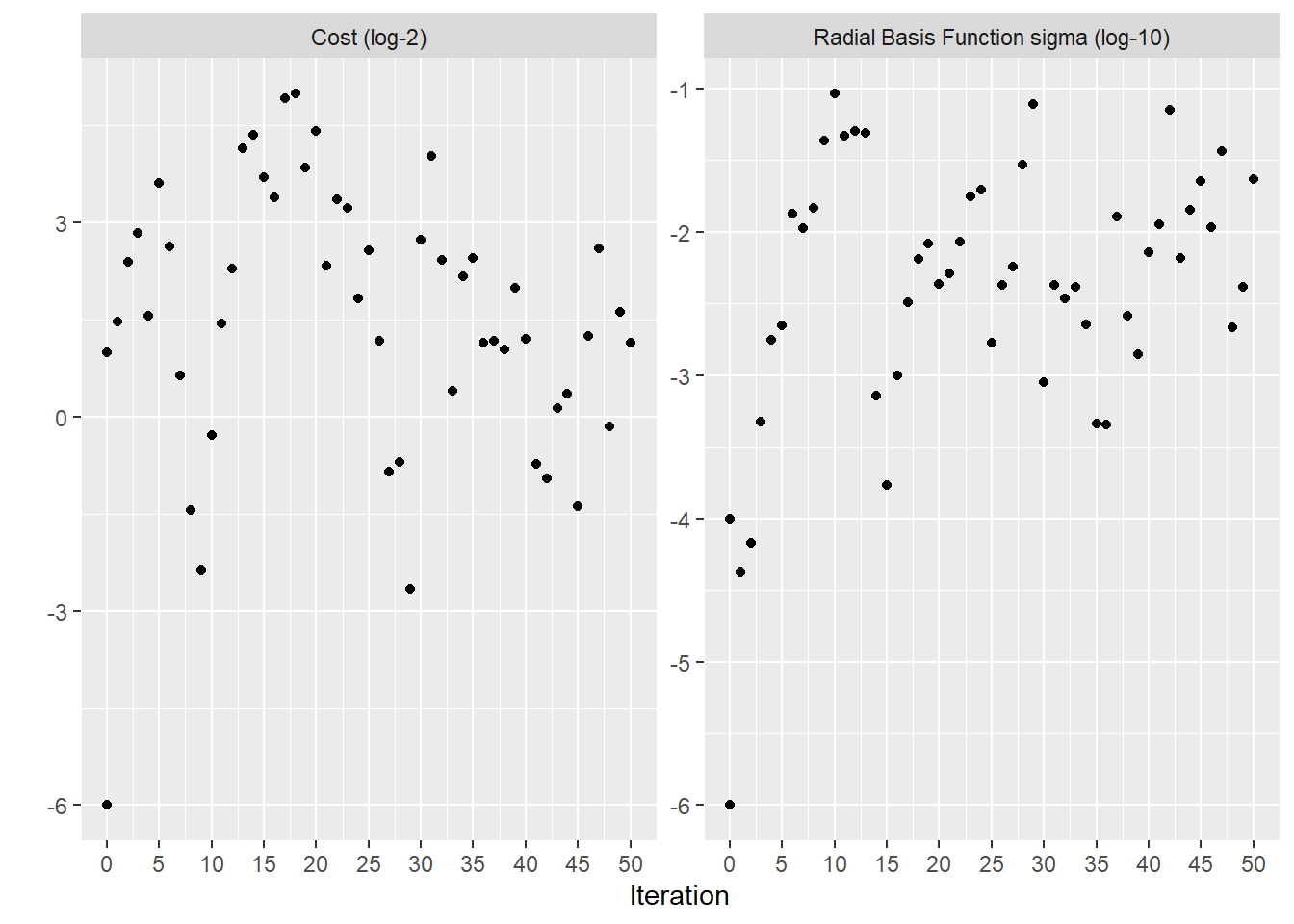
show_best ( svm_bayes_opt ) collect_metrics ( svm_bayes_opt ) autoplot ( svm_bayes_opt , type = "performance" ) # 不同迭代次数下贝叶斯优化过程 autoplot ( svm_bayes_opt , type = "parameters" ) # 超参数随迭代次数的变化情况
模拟退火
模拟退火算法是一种基于全局搜索的优化算法,它通过模拟退火过程来寻找全局最优解。
模拟退火算法的基本思想是:在初始状态下,随机选择一个解,然后按照一定的概率接受该解,并按照一定概率接受相邻的解,直到达到一定温度,算法结束。
tidymodels中使用tune_sim_anneal() tune_bayes() control_sim_anneal()
no_improve:整数对象,在指定次数迭代后仍然没有改进,则停止迭代。被接受或被丢弃的次优值会被标记为“accept suboptimal”或“discard suboptimal”。
restart:整数对象,在指定次数的迭代一直没有出现最佳结果的情况下,重启迭代并重新访问上一个全局最佳超参数并重新开始搜索过程。
radius:0-1间的值,定义初始点周围局部邻域的最小和最大半径。这个半径值只在0.05-0.15之间最为合理。
flip: 概率值,定义每次迭代中改变类别型或整数型超参数值的概率。
cooling_coef:冷却系数,降低该值会使算法对较差结果的接受程度更高。
# A tibble: 5 × 9
cost rbf_sigma .metric .estimator mean n std_err .config .iter
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr> <int>
1 5.04 0.00511 roc_auc binary 0.898 10 0.00833 Iter21 21
2 12.2 0.00222 roc_auc binary 0.898 10 0.00798 Iter5 5
3 2.31 0.00720 roc_auc binary 0.898 10 0.00833 Iter40 40
4 5.36 0.00343 roc_auc binary 0.898 10 0.00808 Iter32 32
5 1.56 0.0106 roc_auc binary 0.898 10 0.00858 Iter7 7
autoplot ( svm_sim_anneal , type = "performance" ) # 不同迭代次数下模拟退火过程 autoplot ( svm_sim_anneal , type = "parameters" ) # 超参数随迭代次数的变化情况
总结
贝叶斯优化使用一个基于现有重抽样结果训练的预测模型来预测新的候选超参数值。
模拟退火通过在超参数空间中随机游走来寻找最优超参数值。
两种方法可以独立使用(initial参数设定为整数),也可以在一个初始的网格搜索后(initial参数设定为tune_grid()对象),用于进一步调优模型超参数。