f(data, truth, ...)8 模型效果的评价指标计算
选择什么样的定量指标来评价模型,对最后模型的选择有着至关重要的作用。如在回归分析中,一般使用最小二乘估计,这最小化了均方误差,使得预测误差最小;如果参数估计时最大化负相关系数\(R^2\),实际上是最大化了因变量的真实值与拟合值的相关系数,一般是不合理的做法.
常见的统计推断性统计模型应用往往是不断在不同模型设定之间进行比较检验,直到不能继续增加或减少解释项.但不管模型拟合的多好,也不能100%断定这个模型就是客观的(这是拟合问题的固有缺陷),这时就需要借助于交叉验证等方法进行预测能力的评估,以确定模型的实际预测能力.
yrakstick是tidymodels系列包中的核心组成包,提供了一系列模型的评估量.
8.1 回归问题的评估
8.1.1 评估指标
回归问题的评估指标有很多,常见的有:
- 均方误差(mean squared error, MSE):预测值与实际值之差的平方和的均值。
- 均方根误差(root mean squared error, RMSE):均方误差的平方根,开方的目的是为了将量纲还原,便于解释。RMSE对异常值非常敏感,极端的异常值会使RMSE变得非常大。如果只是为了衡量模型整体的误差,使用RMSE更加。
- 平均绝对误差(mean absolute error, MAE):预测值与实际值之差的绝对值的均值。MAE对所有的误差一视同仁,不会因为某个异常值的存在而使得整体误差变大。
- 平均绝对百分比误差(Mean Absolute Percentage Error, MAPE):计算预测误差相对 于实际值的百分比的平均值,适用于对预测误差的相对大小更感兴趣的场景。
- 决定系数(coefficient of determination, R-squared, R2):用于衡量模型对数据的拟合程度,取值范围为[0,1],越接近1表示模型拟合效果越好。\(R^2\)衡量了模型解释数据变异的能力。
- 解释方差分数(explained variance score):类似于\(R^2\),值越大表示模型拟合效果越好。
Note
选择合适的评价指标取决于具体的应用场景、数据特性以及分析目的。例如,在某些领域,如金融或库存管理,可能更关心MAPE,因为它提供了关于预测误差相对于实际值比例的信息。而在其他情况下,\(R^2\)或调整后的\(R^2\)可能更适合用来评估模型的整体解释能力。
8.1.2 评估指标的计算
在完成模型拟合后,可以产生测试集上的预测结果,将预测结果存入数据框,使用yardstick包中具有统一界面的评估指标计算函数进行评估,具体形式如下:
- 函数名为
f(). - 保存的预测结果数据集为
data. - 真实结果数据集为
truth. -
...为其他参数,用来定位数据中的预测值,具体见函数文档.
8.1.3 线性回归模型的评估
我们来看一个示例,以ames数据为例:
library(tidymodels)
lm_model <-
linear_reg() %>%
set_engine("lm")
ames_rec <-
recipe(
Sale_Price ~
Neighborhood +
Gr_Liv_Area +
Year_Built +
Bldg_Type +
Latitude +
Longitude,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_interact(~ Gr_Liv_Area:starts_with("Bldg_Type_")) %>%
step_ns(Latitude, Longitude, deg_free = 10)
lm_workflow <-
workflow() %>%
add_model(lm_model) %>%
add_recipe(ames_rec)
lm_fit <-
lm_workflow %>%
fit(ames_train)为了演示,这里用ames_test当作验证数据集,情况下应该单独生成验证数据集或者使用训练集的随机抽样交叉验证.在验证数据集上进行预测,生成因变量的预测值:
ames_test_res <- predict(
lm_fit,
new_data = ames_test # 预测时不需要因变量
)
ames_test_res %>%
slice_head(n = 5)# A tibble: 5 × 1
.pred
<dbl>
1 5.28
2 5.27
3 5.22
4 5.08
5 5.14# 将预测结果与验证集中的真实数据合并
ames_test_res <- ames_test %>%
bind_cols(ames_test_res)
ames_test_res %>%
slice_head(n = 5)# A tibble: 5 × 75
MS_SubClass MS_Zoning Lot_Frontage Lot_Area Street Alley Lot_Shape
<fct> <fct> <dbl> <int> <fct> <fct> <fct>
1 Two_Story_1946_and_New… Resident… 74 13830 Pave No_A… Slightly…
2 Two_Story_1946_and_New… Resident… 78 9978 Pave No_A… Slightly…
3 One_Story_PUD_1946_and… Resident… 26 5858 Pave No_A… Slightly…
4 Two_Story_PUD_1946_and… Resident… 21 1680 Pave No_A… Regular
5 One_Story_PUD_1946_and… Resident… 53 4043 Pave No_A… Regular
# ℹ 68 more variables: Land_Contour <fct>, Utilities <fct>, Lot_Config <fct>,
# Land_Slope <fct>, Neighborhood <fct>, Condition_1 <fct>, Condition_2 <fct>,
# Bldg_Type <fct>, House_Style <fct>, Overall_Cond <fct>, Year_Built <int>,
# Year_Remod_Add <int>, Roof_Style <fct>, Roof_Matl <fct>,
# Exterior_1st <fct>, Exterior_2nd <fct>, Mas_Vnr_Type <fct>,
# Mas_Vnr_Area <dbl>, Exter_Cond <fct>, Foundation <fct>, Bsmt_Cond <fct>,
# Bsmt_Exposure <fct>, BsmtFin_Type_1 <fct>, BsmtFin_SF_1 <dbl>, …- 可大致流量两列:
Sale_Price和.pred,大致了解下预测精度. - 注意因变量的真实值和预测值都是对数变换的结果,在评估模型效果时,一般使用建模时的因变量形式,而不是转换成原始形式再评估.
- 可以做散点图显示两者间的关系.
ggplot(ames_test_res, aes(x = Sale_Price, y = .pred)) +
geom_point(alpha = 0.5) +
geom_abline(lty = 2) + # 没有指定系数a,b,则使用其默认值,分别为0,1
labs(
x = "Predicted Sale Price (log10)",
y = "Sale Price (log10)"
) +
coord_obs_pred() # 坐标轴设置:令x,y轴的范围一致,使用相同的长度单位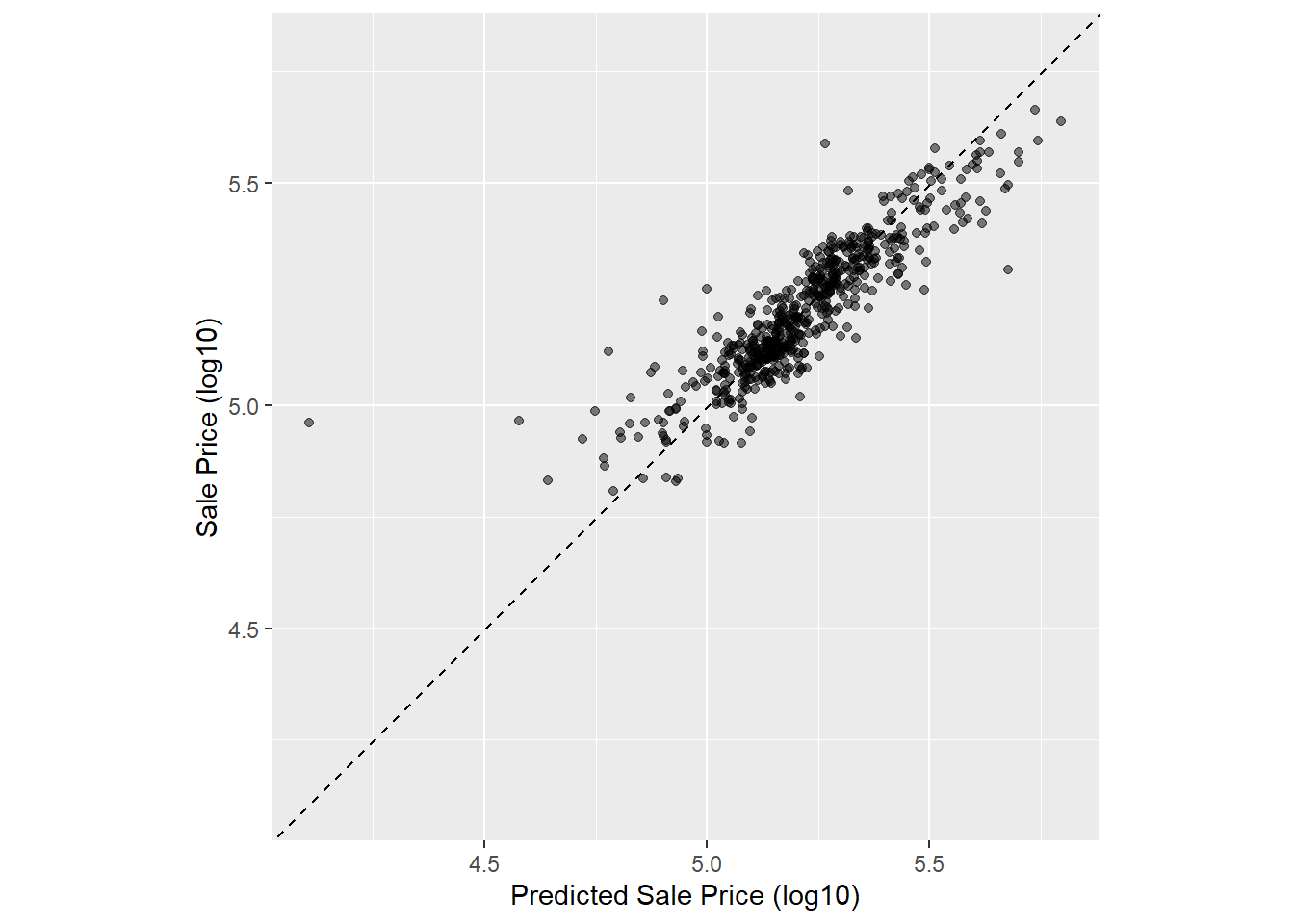
在有了保存因变量的预测值和真实值的数据集后,可以使用yardstick包中的评估函数进行模型效果的评估. yardstick包的reference页面 可以查看所有评价指标的函数。
rmse(
ames_test_res,
truth = Sale_Price,
estimate = .pred
)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.0842如果需要同时计算多个模型的评估指标,可以使用yardstick包中的metric_set()函数对多个评估指标进行组合.
ames_metrics <- metric_set(rmse, rsq, mae)
ames_metrics(
ames_test_res,
truth = Sale_Price,
estimate = .pred
)# A tibble: 3 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.0842
2 rsq standard 0.790
3 mae standard 0.0564上述代码分别计算了均方根误差(RMSE),决定系数(R方),平均绝对误差(MAE):
- RMSE和MAE: 与因变量量纲相同,衡量预测值与真实值之间的平均距离,越小越好.
- R方: 衡量预测值与真实值之间的相关程度,越接近1越好.
8.1.4 随机森林模型的评估
rf_model <-
rand_forest(trees = 1000) %>%
set_engine("ranger") %>%
set_mode("regression")
rf_workflow <-
workflow() %>%
add_model(rf_model) %>%
add_formula(
Sale_Price ~
Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type + Latitude + Longitude
) # 此处并未将因子转化为哑变量,随机森林模型不需要这个转化
rf_fit <- rf_workflow %>%
fit(ames_train)
ames_test_res_rf <- predict(
rf_fit,
new_data = ames_test
)
ames_test_res_rf <- ames_test %>%
bind_cols(ames_test_res_rf)
ames_test_res_rf# A tibble: 586 × 75
MS_SubClass MS_Zoning Lot_Frontage Lot_Area Street Alley Lot_Shape
<fct> <fct> <dbl> <int> <fct> <fct> <fct>
1 Two_Story_1946_and_Ne… Resident… 74 13830 Pave No_A… Slightly…
2 Two_Story_1946_and_Ne… Resident… 78 9978 Pave No_A… Slightly…
3 One_Story_PUD_1946_an… Resident… 26 5858 Pave No_A… Slightly…
4 Two_Story_PUD_1946_an… Resident… 21 1680 Pave No_A… Regular
5 One_Story_PUD_1946_an… Resident… 53 4043 Pave No_A… Regular
6 One_Story_1946_and_Ne… Resident… 90 11520 Pave No_A… Regular
7 Split_or_Multilevel Resident… 67 13300 Pave No_A… Slightly…
8 One_Story_1946_and_Ne… Resident… 59 10593 Pave No_A… Slightly…
9 Two_Story_1946_and_Ne… Resident… 98 12256 Pave No_A… Slightly…
10 One_Story_1946_and_Ne… Floating… 75 9000 Pave No_A… Regular
# ℹ 576 more rows
# ℹ 68 more variables: Land_Contour <fct>, Utilities <fct>, Lot_Config <fct>,
# Land_Slope <fct>, Neighborhood <fct>, Condition_1 <fct>, Condition_2 <fct>,
# Bldg_Type <fct>, House_Style <fct>, Overall_Cond <fct>, Year_Built <int>,
# Year_Remod_Add <int>, Roof_Style <fct>, Roof_Matl <fct>,
# Exterior_1st <fct>, Exterior_2nd <fct>, Mas_Vnr_Type <fct>,
# Mas_Vnr_Area <dbl>, Exter_Cond <fct>, Foundation <fct>, Bsmt_Cond <fct>, …ames_metrics <- metric_set(rmse, rsq, mae)
ames_metrics(
ames_test_res_rf,
truth = Sale_Price,
estimate = .pred
)# A tibble: 3 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.0746
2 rsq standard 0.841
3 mae standard 0.0478线性回归的MAE为0.056,随机森林的MAE为0.0478,随机森林的拟合效果略优.但这只是一次划分测试集和训练集得到的结果,更好的比较方法是利用重抽样技术,具体见 Chapter 9 和 Chapter 10.
8.2 二分类问题的评估
二分类模型的性能评价指标为ROC曲线,ROC曲线是二分类机器学习模型的性能评价指标,已知测试集或验证集每个样本的真实类别及其模型预测概率值,就可以计算并绘制ROC曲线。
ROC曲线是不同分类阈值上对比真正率(TPR)与假正率(FPR)的曲线,可以通过下图的步骤进行计算。
 {#fig-counfusion-matrix}
{#fig-counfusion-matrix}
通过以上定义,我们梳理执行第一步:对问题进行梳理。本例的问题可以分解为如小问题:
- 让分类阈值以某步长在[0,1]上变化取值;
- 对某一个阈值:
- 计算预测类别
- 计算混淆矩阵
- 计算真正率和假正率
- 循环迭代,计算所有阈值的真正率和假正率;
- 绘制ROC曲线。
8.2.1 混淆矩阵相关的其他指标
- 准确率(accuracy):预测正确的样本数占总样本数的比例,即所有被分类正确的样本数占总样本数的比例。
- 精确率(percision):也叫查准率,表示被分类为正例的样本中实际为正例的比例。
- 召回率(recall):也叫查全率,或灵敏度(sensitivity),表示实际为正例的样本中被正确分类为正例的比例。
- F1分数:精确率和召回率的加权平均值,越高说明模型越稳健。
- 特异度(specificity):所有实际为负例/阴性的样本中,被正确分为为阴性的比例。
在评估模型预测概率准确率时,以下指标也非常重要:
- 马修斯相关系数(Matthews Correlation Coefficient,MCC):同时考虑混淆矩阵中4个类别的结果,并综合考量,范围是 [-1,1],1 表示完美预测,0 表示随机预测,-1 表示完全相反。尤其适用于类不平衡的二分类问题。
- 均衡准确率(Balanced Accuracy):当出现类别不平衡时,使用准确率评价可能会出现 较大偏差,此时可以使用均衡准确率,它是每个类别中预测正确的比例的算术平均值。
- Log Loss(交叉熵损失):又叫对数损失、对数似然、逻辑损失,特别适用于概率预测 模型,衡量预测概率分布与实际类别之间的差异。越接近 0 越好。
- Brier-Score:布里尔分数,衡量模型预测的类别的概率与真实值之间的误差,仅用于 二分类数据,范围是 0 到 1,越小越好。
- 校准曲线(Calibration plot):衡量模型预测的概率和真实概率的差异,是一种比单 纯评价分类准确性更加精确的评价指标。
- 预测概率直方图:评价模型预测概率的分布,并据此判断模型的置信度,临床预测模型中叫校准度。
根据以上步骤,我们使用一个心脏病诊断数据集进行演示.
Heart <- read_csv("data/Heart.csv") %>%
# select(-1) %>%
mutate(
ChestPainType = factor(
ChestPainType,
levels = c(
"asymptomatic",
"nonanginal",
"nontypical",
"typical"
)
),
Thal = factor(Thal, levels = c("fixed", "normal", "reversable")),
AHD = factor(AHD, levels = c("Yes", "No"))
) %>%
drop_na()
glimpse(Heart)生成训练集和测试集:
set.seed(101)
split <- initial_split(Heart, prop = 0.60)
heart_train <- training(split)
heart_test <- testing(split)预处理,建立工作流,在训练集上拟合模型:
heart_rec <- recipe(
AHD ~ .,
data = heart_train
) %>%
step_dummy(all_nominal_predictors())
lgs_model <- logistic_reg() %>%
set_engine("glm")
lgs_wf <- workflow() %>%
add_model(lgs_model) %>%
add_recipe(heart_rec)
lgs_fit <- fit(lgs_wf, heart_train)
# 在测试集上预测, 生成预测类别、每类的后验概率, 并添加真实类别结果:
heart_test_res <- predict(
lgs_fit,
new_data = heart_test %>% select(-AHD) # 预测分类结果
) %>%
bind_cols(
predict(
lgs_fit,
new_data = heart_test %>% select(-AHD),
type = "prob" # 预测结果各分类概率
)
) %>%
bind_cols(heart_test %>% select(AHD)) # 与真实值合并
heart_test_res %>%
slice_head(n = 5) %>%
knitr::kable()
# 显示混淆矩阵
conf_mat(heart_test_res, truth = AHD, estimate = .pred_class)
# 同时计算多个评估指标
classification_metrics <- metric_set(
accuracy,
mcc,
f_meas
)
classification_metrics(
heart_test_res,
truth = AHD,
estimate = .pred_class
)- 准确率和MCC同时评估两类的正确预测,而F1指标更强调能够将正例检出.
-
tidymodels默认第一个水平为正例,可以用event_level指定一个水平为正例(事件).
ROC曲线、计算AUC值,则需要使用预测的后验概率而不是类别.用roc_curve()计算ROC曲线上点的坐标,如:
heart_roc <- roc_curve(
heart_test_res,
AHD,
.pred_Yes
)
heart_roc %>%
slice_head(n = 5)
# 绘制ROC曲线
autoplot(heart_roc)
# 计算AUC值
roc_auc(heart_test_res, AHD, .pred_Yes)8.3 多分类问题的评估
使用iris数据集拟合随机森林模型为例,不区分训练集和测试集,而使用交叉验证的方法( Chapter 9)进行模型评估.
iris_recipe <-
recipe(Species ~ ., data = iris)
rf_model <-
rand_forest(
trees = 100,
min_n = 5
) %>%
set_engine("ranger") %>%
set_mode("classification")
rf_workflow <-
workflow() %>%
add_model(rf_model) %>%
add_recipe(iris_recipe)生成交叉验证分组,用交叉验证样本拟合模型并进行评估.
set.seed(101)
iris_folds <- vfold_cv(iris, v = 10)
keep_pred <- control_resamples(
save_pred = TRUE,
save_workflow = TRUE
)
iris_cv <- rf_workflow %>%
fit_resamples(resamples = iris_folds, control = keep_pred)
iris_cv# Resampling results
# 10-fold cross-validation
# A tibble: 10 × 5
splits id .metrics .notes .predictions
<list> <chr> <list> <list> <list>
1 <split [135/15]> Fold01 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
2 <split [135/15]> Fold02 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
3 <split [135/15]> Fold03 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
4 <split [135/15]> Fold04 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
5 <split [135/15]> Fold05 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
6 <split [135/15]> Fold06 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
7 <split [135/15]> Fold07 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
8 <split [135/15]> Fold08 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
9 <split [135/15]> Fold09 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]>
10 <split [135/15]> Fold10 <tibble [3 × 4]> <tibble [0 × 4]> <tibble [15 × 7]># 从交叉验证结果提取预测值、后验概率
assess_res <- collect_predictions(iris_cv)
str(assess_res)tibble [150 × 8] (S3: tbl_df/tbl/data.frame)
$ .pred_class : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 2 2 2 2 2 3 3 ...
$ .pred_setosa : num [1:150] 1 1 1 0 0 0 0 0.005 0 0 ...
$ .pred_versicolor: num [1:150] 0 0 0 0.814 1 ...
$ .pred_virginica : num [1:150] 0 0 0 0.187 0 ...
$ id : chr [1:150] "Fold01" "Fold01" "Fold01" "Fold01" ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 2 2 2 2 2 3 3 ...
$ .row : int [1:150] 5 9 46 53 83 90 93 99 116 124 ...
$ .config : chr [1:150] "pre0_mod0_post0" "pre0_mod0_post0" "pre0_mod0_post0" "pre0_mod0_post0" ...# 显示混淆矩阵
conf_mat(
assess_res,
Species,
.pred_class
) Truth
Prediction setosa versicolor virginica
setosa 50 0 0
versicolor 0 47 3
virginica 0 3 47# 计算多个评估指标
classification_metrics <- metric_set(
accuracy,
mcc
)
classification_metrics(assess_res, truth = Species, estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy multiclass 0.96
2 mcc multiclass 0.94原来适用于二分类的评价指标都可以设法推广到多类别分类问题, 推广方法有(设有个类别):
使用相应指标计算函数的
estimator选项可以指定推广方法.- 宏平均法,将每个类别与“其它”类别作二分类计算, 将获得的个评估指标计算平均值.
- 宏加权法,类似宏平均法, 但是计算平均值时按每类的样例数加权.
- 微平均法,对每个类分别计算对评估指标的贡献, 将这些贡献汇总计算成一个单一指标.
例如sensitivity()函数在二分类问题占用可以计算敏感度(将正例识别为正例的概率),用宏平均法推广到多分类.
# 计算敏感度的推广指标
sensitivity(
assess_res,
truth = Species,
estimate = .pred_class,
estimator = "macro" # "macro"为使用为平均法,"macro_weighted"为使用宏加权法
)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 sensitivity macro 0.96# 计算AUC的推广指标
roc_auc(
assess_res,
truth = Species,
.pred_setosa,
.pred_versicolor,
.pred_virginica
)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc hand_till 0.994