Tidymodels with R-读书笔记
前言-机器学习简介
机器学习的基本概念和方法
统计学习(statistical learning), 也有数据挖掘(data mining),机器学习(machine learning)等称呼。 主要目的是用一些计算机算法从大量数据中发现知识。 方兴未艾的数据科学就以统计学习为重要支柱。 方法分为有监督(supervised)学习与无监督(unsupervised)学习。
无监督学习方法如聚类问题、主成分分析、异常点识别、购物篮问题等。
有监督学习即统计中回归分析和判别分析解决的问题, 现在又有回归判别数、随机森林、lasso、梯度提升法、支持向量机、 神经网络、贝叶斯网络、排序算法等许多方法。
无监督学习在给了数据之后, 直接从数据中发现规律, 比如聚类分析是发现数据中的聚集和分组现象, 购物篮分析是从数据中找到更多的共同出现的条目 (比如购买啤酒的用户也有较大可能购买火腿肠)。
有监督学习方法众多。 通常,需要把数据分为训练样本(training sample)和测试样本(testing sample), 训练样本的因变量(数值型或分类型)是已知的, 根据训练样本中自变量和因变量的关系训练出一个回归函数, 此函数以自变量为输入, 可以输出因变量的预测值。
训练出的函数有可能是有简单表达式的(例如,logistic回归)、 有参数众多的表达式的(如神经网络), 也有可能是依赖于所有训练样本而无法写出表达式的(例如k近邻分类)。
偏差与方差折衷
对于回归问题,我们经常需要使用均方误差(MSE) \(E|Ey-\hat{y}|^2\) 来衡量精度。对于分类问题,经常使用分类准确率等来衡量精度。 均方误差可以分解为以下公式:
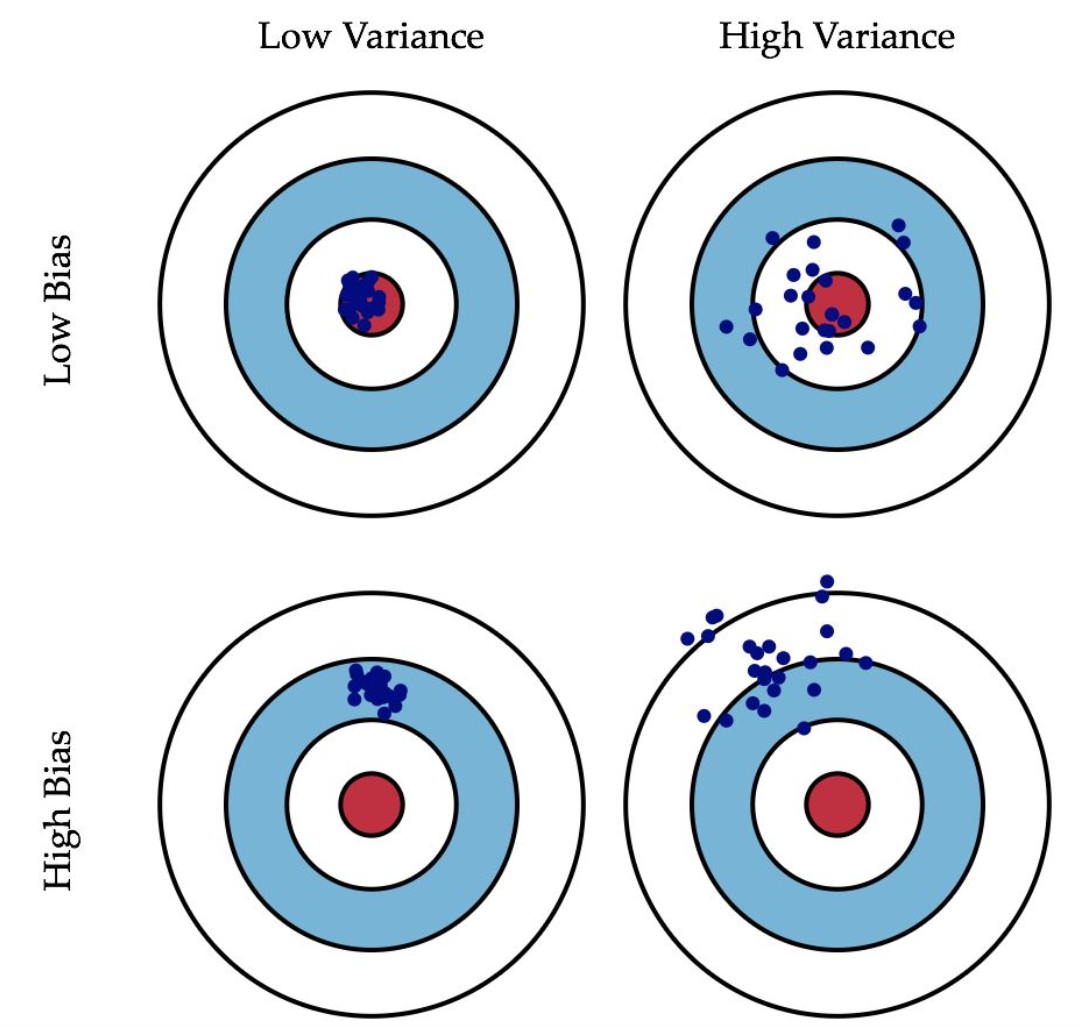
\[ 均方误差=方差+偏差^2 \]
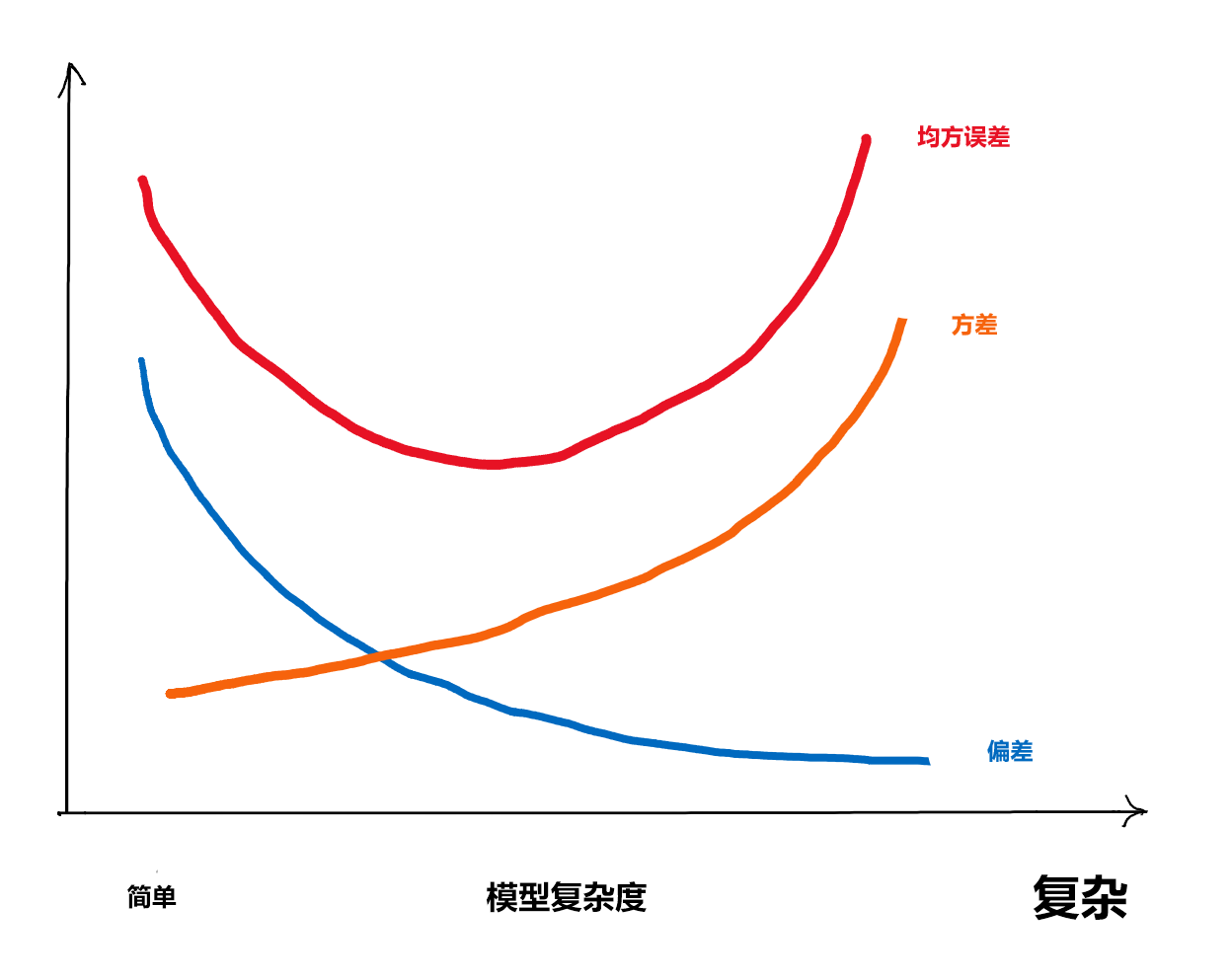
如果选择的模型过于简单, 即模型复杂度过低, 则偏差会很大, 方差会很小; 随着模型的复杂度提升,模型的预测能力越来越强,会使得偏差逐渐降低;同时,如果模型过于复杂,会使方差过大,同样导致模型的预测能力不足(过拟合)。
复杂程度在线性回归中就是自变量个数,在一元曲线拟合中就是曲线的不光滑程度。在其它指标类似的情况下,简单的模型更稳定、可解释更好,所以统计学特别重视模型的简化。
交叉验证
即使是在从训练样本中训练(估计)回归函数时,也需要适当地选择模型的复杂度。仅考虑对训练数据的拟合程度是不够的,这会造成过度拟合问题。
为了相对客观地度量模型的预报误差,假设训练样本有个观测,可以留出第一个观测不用,用剩余的 \(n-1\) 个观测建模,然后预测第一个观测的因变量值,得到一个误差;对每个观测都这样做,就可以得到个误差。这样的方法叫做留一法。这种方法想法简单,但除了样本量特别小的情况以外,这种方法从计算效率和统计性质上都是不好的,
更常用的是十折或五折交叉验证。假设训练集有个观测,将其用随机抽样方法随机地均分成份,保留第1份不用,将其余9份合并在一起用来建模,然后预报第一份;对每一份都这样做,并在每一份上计算评估预测精度的指标,取这10份上的精度指标的平均值作为预测精度指标,这样的模型预测精度评估方法叫做十折交叉验证(ten-fold cross validation)方法。
因为要预报的数据没有用来建模,交叉验证得到的误差估计更准确。
rsample的vfold_cv可以生成这样的划分,并对每一份,可以用analysis()和assessment()分别提取建模用部分和验证用部分。机器学习算法函数一般都包含了用交叉验证方法调参的功能,不需要用户自己去划分数据。
交叉验证和重采样的具体描述在 9 评估模型性能-重采样 中有详细介绍。
回归问题的评判指标
对于回归类的问题,设自变量为 \(x_i\) ,因变量为 \(y_i\) ,用模型得到的因变量预测值(估计值) \(\hat{y}_i, i = 1, 2, ..., n\),则常用的回归评判指标是均方根误差,如下 Equation 1 所示:
\[ RMSE=\sqrt{\frac{1}{n}\sum_{i=1}^n(y_i-\hat{y}_i)^2} \tag{1}\]
值得注意的是,为了避免过拟合,计算 \(\hat{y}_i\) 所用的模型参数,应该从与上述数据无关的训练集中获取。
判别问题的评判指标
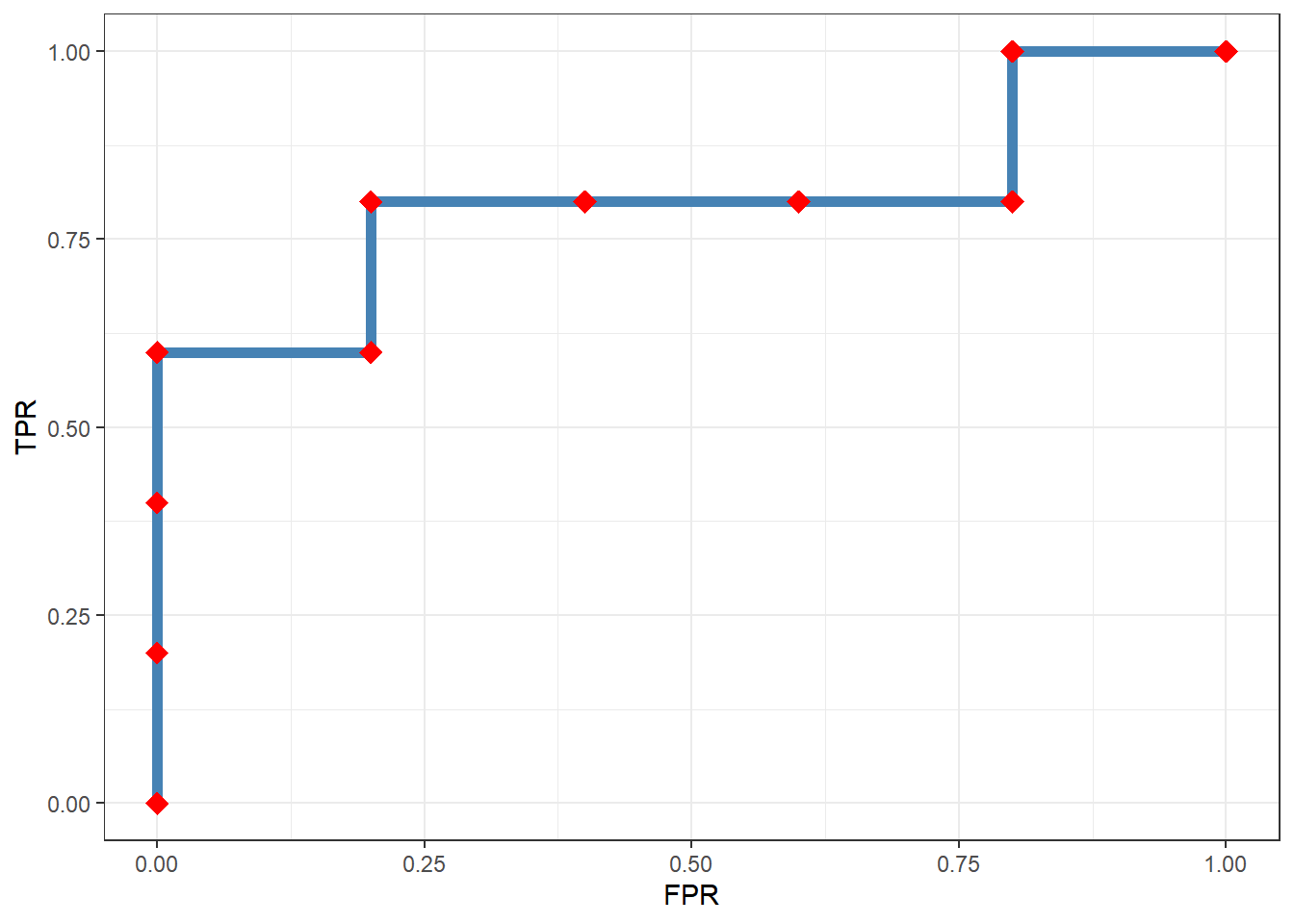
有监督学习问题的因变量取为分类值时,这样的问题称为判别问题。这类问题常用ROC曲线(receiver operating characteristic curve)来评判模型的预测能力。如下 图 2 (b) 所示,ROC曲线横轴是假阳率(false positive rate),纵轴是真阳率(true positive rate),曲线的形状反映了模型的预测能力:
- ROC曲线越靠近左上角,说明模型的预测能力越好,因为它能够准确地将正例预测为正例,也能够准确地将负例预测为负例。
- 也可以用ROC曲线的下方的面积,即AUC(area under curve)值来衡量模型的预测能力,AUC值越大,说明模型的预测能力越好。