library(tidymodels)
tidymodels_prefer()
simple_ames <-
recipe(
Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_dummy(all_nominal_predictors())
simple_ames7 使用recipes进行特征工程
所有的recipe的step_**()函数均可在tidymodels.org/find中搜索查询.
7.1 AMES数据集示例
已ames数据集为例,进行简单的特征工程示例. 仅考虑如下几个自变量:
- neighborhood, 分类变量,训练集中共有29个不同取值;
- Gr_Liv_Area,数值型变量,总的达标居住面积;
- Year_Built,建造年份;
- Bldg_Type,房屋类型,分类变量,可取:
- OneFam;
- TwoFmCon;
- Duplex;
- Twnhs;
一个recipe用step_**()函数指定数据的预处理步骤,但暂不进行实际的计算(只说明在预处理时应该做什么):
上面的程序中:
- 用
recipe()函数添加了因变量和自变量集合(没有指定对自变量的变换),以及训练数据集. - 用
step_log对变量Gr_Liv_Area指定了作常用对数变换. - 用
step_dummy指定了将已选定的自变量集合中所有分类变量转换为哑变量形式( Section 7.3 对哑变量有深入讨论.)
在recipe环境下: - all_nominal_predictors()表示所有分类自变量变量 - all_numeric_predictors()表示所有数值型自变量 - all_predictors()表示所有自变量 - all_outcomes()表示所有因变量 - step_*函数中可以指定多个变量,只要原样写变量名(不用撇号保护)并用逗号分隔.
使用recipe()处理变量,而不是直接使用R的公式界面,或直接指定变量,有以下优点:
- 如果使用了不同的模型,这些变换可以在不同模型之间共用.
-
recipe拥有更多的预处理选项,可以更好地控制数据预处理过程.如使用all_nominal_predictors()函数,可以自动识别所有分类变量. - 所有的数据预处理过程都可以在一个对象中完成,而不是在脚本或不同的代码块中重复.
7.2 使用recipe
recipe是workflow的一部分,在workflow中加入recipe,是更灵活更高级的数据预处理方式.
workflow只能有一种recipe方式,不能在使用add_formula()或add_variables()之后再使用recipelm_model <- linear_reg() %>%
set_engine("lm")
lm_wflow <- workflow() %>%
add_model(lm_model) %>%
add_recipe(simple_ames)
lm_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_log()
• step_dummy()
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm - 上诉代码中,
add_recipe()函数将simple_ames加入到workflow中,并指定了模型为lm_model.再次注意,此时只是对预处理过程进行了定义,并未进行实际的转换.实际的计算发生在模型拟合的过程中,即使用fit()函数后。 - 在输出结果中,可以看到
recipe的具体步骤(Preprocessor字段),如step_log()和step_dummy()等.
lm_fit <- lm_wflow %>%
fit(ames_train)
lm_fit %>%
predict(ames_test %>% slice(1:3))# A tibble: 3 × 1
.pred
<dbl>
1 5.28
2 5.28
3 5.22predict(lm_fit, new_data = ames_test %>% slice(1:3))# A tibble: 3 × 1
.pred
<dbl>
1 5.28
2 5.28
3 5.22在用predict()对测试集进行预测时,也会在测试集上调用食谱进行预处理,但这些预处理的参数还是使用从训练集得到的参数,比如,如果预处理是对变量作标准化,即减去变量均值后除以变量标准差,均值和标准差都是在训练集上计算,用predict()对测试集进行预测时的变量标准化仍使用训练集上计算的变量均值和标准差.
如果想查看实际的预处理结果,可以使用extract_recipe()函数从拟合结果中提取出已经计算的预处理结果.
lm_fit %>%
extract_recipe(estimated = TRUE)extract_fit_parsnip()可以从拟合结果中提取与模型和引擎计算有关的内容,即模型的估计结果.
lm_fit %>%
extract_fit_parsnip() %>% # 提取模型和引擎相关的内容
tidy()# A tibble: 35 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -0.649 0.225 -2.89 3.92e- 3
2 Gr_Liv_Area 0.616 0.0139 44.4 7.33e-312
3 Year_Built 0.00199 0.000113 17.6 7.35e- 65
4 Neighborhood_College_Creek 0.0159 0.00811 1.96 4.99e- 2
5 Neighborhood_Old_Town -0.0290 0.00826 -3.51 4.58e- 4
6 Neighborhood_Edwards -0.0492 0.00758 -6.48 1.10e- 10
7 Neighborhood_Somerset 0.0535 0.00942 5.69 1.46e- 8
8 Neighborhood_Northridge_Heights 0.139 0.00983 14.1 1.37e- 43
9 Neighborhood_Gilbert -0.0290 0.00918 -3.16 1.62e- 3
10 Neighborhood_Sawyer -0.00652 0.00826 -0.789 4.30e- 1
# ℹ 25 more rows# 或直接使用tidy()函数即可。在 ?sec-dim-reductrion-recipes 中,有更多在workflow对象之外使用recipe的示例.
7.3 典型的预处理流程
recipe包通过step_**()系列函数提供各种常见的预处理功能.
7.3.1 将类别变量转为数值型变量-以数字格式对定性数据进行编码-dummy-哑变量
-
step_dummy()函数将类别变量转换为哑变量. -
step_unknown()将缺失值更改为专用的因子水平. -
step_novel()为指定的类别变量预留一个原来没有但将来可能出现的因子水平. -
step_other()可以统计各水平的函数,并将低频的水平值合并到一个”other”类别中.
simple_ames <-
recipe(
Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01) %>% # 总样本量小于1%的类别合并到"other"类别
step_dummy(all_nominal_predictors())
simple_ames
Note
- 多数模型需要将类别变量转换为数值型变量,但基于树的模型,基于规则的模型,朴素贝叶斯模型则不需要进行转换.
-
step_dummy()是进行标准解压变量变换的函数,变换后的命名格式为”变量名_类别值”.
除了最常见的哑变量编码方式,recipe还支持其他编码方式,我们将在 Chapter 16 中详细介绍.
7.3.2 交互作用项
step_interact()函数可以生成交互作用项: - 如果两个变量都是数值型的,交互作用效应为二者的乘积. - 如果两个变量都是类别型的,交互作用效应为两个变量所有组合建立的哑变量编码. - 如果两个变量既有数值型又有类别型,则交互作用效应是类别型变量每个类别分别计算数值型变量的系数(斜率).
simple_ames <-
recipe(
Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhoods, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
# 注意,以下代码中的Gr_Liv_Area是已经经过log变换的变量
step_interact(~ Gr_Liv_Area:starts_with("Bldg_Type_"))
simple_ames上述代码中,step_interact()建立了数值型的Gr_Liv_Area的对数变换与已经做过哑变量编码的Bldg_Type之间的交互作用效应. 由变量a, b产生的交互作用效应变量命名为a_x_b的格式.
7.3.3 样条函数项
样条函数(Spline Function)是一种在数学和计算机科学中广泛使用的函数,用于插值和曲线拟合.它是一种分段定义的多项式函数,每一段上是一个多项式,但整体上保持光滑连续.用若干样条函数值代替原数据点,可以使得数据更加平滑,提供了更加灵活的非线性拟合能力.
在数据中增加更多的样条项(即增加自由度),虽然可以提升拟合效果,但也容易产生过拟合,在使用中要时刻注意
在ggplot中geom_smooth()函数可以用来绘制样条函数.
library(patchwork)
library(splines)
plot_smoother <- function(deg_free) {
ggplot(ames_train, aes(x = Latitude, y = 10^Sale_Price)) +
geom_point(alpha = 0.2) +
scale_y_log10() +
geom_smooth(
method = "lm",
formula = y ~ ns(x, df = deg_free),
se = FALSE
) +
labs(
title = paste(deg_free, "Spline Terms"),
y = "Sale Price (USD)"
)
}
(plot_smoother(2) + plot_smoother(5)) /
(plot_smoother(20) + plot_smoother(100))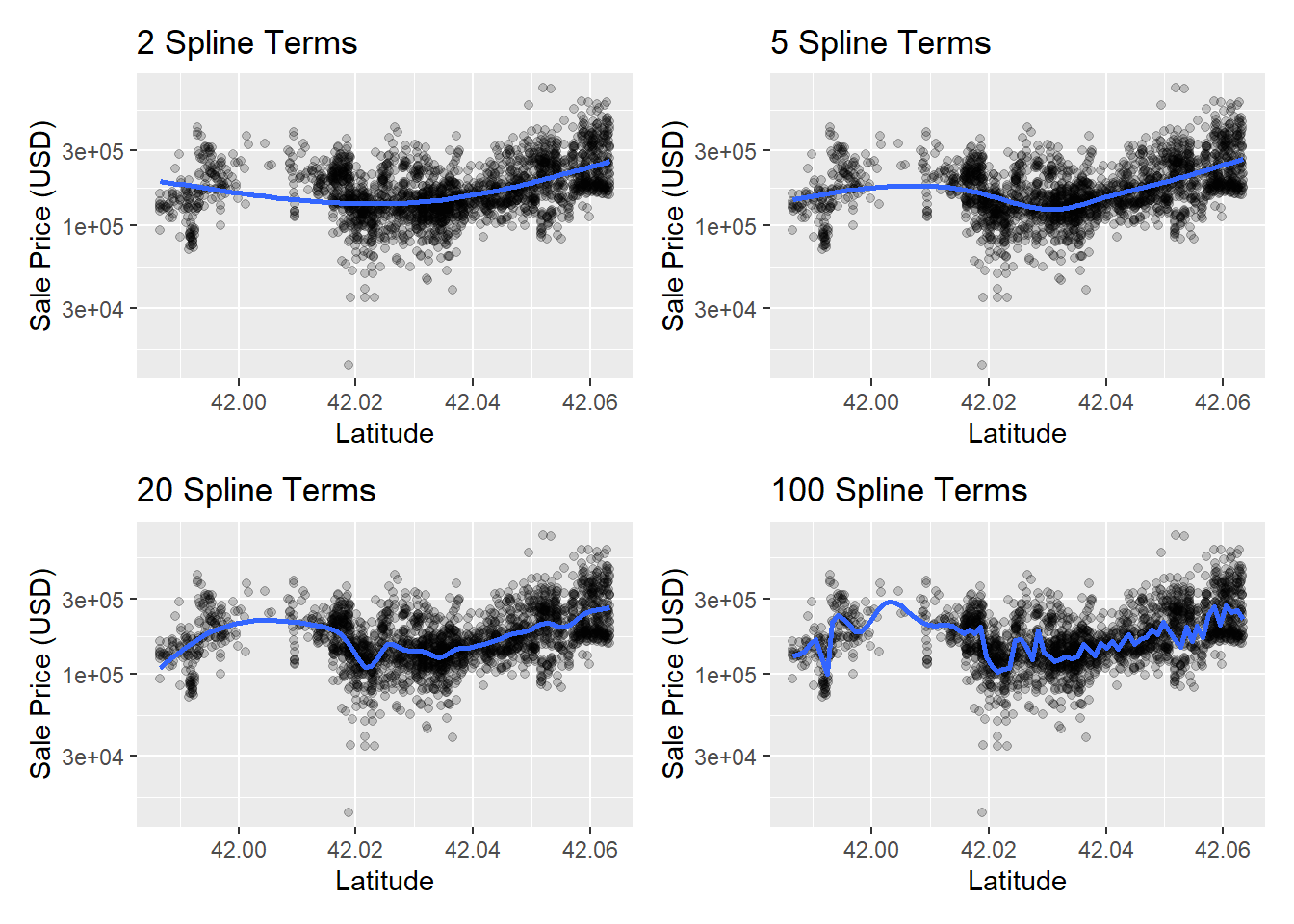
图 7.1 中有些面板的拟合效果明显不佳:
- 2个项与数据拟合 不足,而 100 个项与数据拟合过度.
- 有5个项和20个项的面板看起来拟合得相当平滑,抓住了数据的主要模式.
- 这表明适当的 “非线性”程度非常重要.因此,样条项的数量可视为该模型的一个调整参数. Chapter 11 将继续探讨这类参数.
通过recipes包添加样条变换项的例子:
splines_ames_recipe <-
recipe(
Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhoods, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_interact(~ Gr_Liv_Area:starts_with("Bldg_Type_")) %>%
step_ns(Latitude, deg_free = 20)7.3.4 特征提取
预处理经常需要根据旧有变量计算产生对预测因变量更有用的新变量. 比如,主成分分析(PCA)就是一种消除旧有变量中的相关性并获得压缩结果的方法. 例如,ames数据中与面积大小有关的变量相关性强,可以进行压缩,代码如下:
step_pca(matches("(SF$)|(Gr_Liv)"))- 上述代码中,使用
matches()指定变量名符合特定模式的变量子集. - 如果各个变量量纲不同,应该先用
step_normalize()将变量转换到相近的取值范围. - 除了主成分分析以外,
recipes还支持其它一些变换方法,如立分量分析(ICA)、非负矩阵因式分解(NNMF)、多维缩放(MDS)、均匀流形逼近和投影(UMAP)等.具体可参见recipes的预处理方法.
7.3.5 对观测进行抽样
在分类问题中,如果两个类别的比例相差很大,很容易忽略频率较少的类.为此可以对训练样本的观测进行抽样,产生新的训练样本:
- 可以减数抽样,保持少数派观测不变,对多数派样本仅抽取其中一部分;
- 可以增殖抽样,保持多数派观测不变,对少数派进行抽样增加,增加方式可能是简单地重复,也可能是产生与少数派表现相同但不同的样本.
- 可以对多数派抽取一部分,对少数派增加样品.
themis包能够进行这些操作,比如,减数抽样可用:
step_downsample(outcome_column_name)这些对样本行的增删应该仅对训练样本进行,测试样本和其它保留的样本不应该进行这些操作.这些函数设置了一个skip参数,默认为TRUE,就是规定这样的原则.
还有一些操作样本行的函数,如step_filter(), step_sample(),step_slice(), step_arrange().这些函数的skip参数默认均为TRUE.
7.3.6 更一般的变换
对数值变量作对数变换,仅是许多能做的变换之一,显然不可能将每个变换都制作一个step_*()函数.可以用step_mutate()指定变换方法,类似于dplyr包的mutate()函数用法.
这些一般的变换要避免使用测试集信息,比如,在step_mutate()中规定了x = w > mean(w),则其中的mean(w)在测试集上会使用测试集的w均值,而不是使用训练数据中w的均值。 更多可参看 Section 7.3.8。
7.3.7 自然语言处理
textrecipes包能够对自然语言输入转换成结构化的输入数据,如将文本字符串内容分词,筛选,计算文本统计量等.
7.3.8 对测试集应避免的预处理
如果需要对因变量进行变换,其不应该作为预处理的一部分.
例如,ames数据集中,我们设定Sale_Price列为因变量(或结果变量),那么在对其进行对数变换时,不应该将其包含在step_log()函数中,而是应该在recpie之外对其进行转换,即ames <- ames %>% mutate(Sale_Price = log10(Sale_Price)),而不是step_log(Sale_Price, base = 10)。
如前所述,如果对数据行进行了一些操作,比如减数抽样,应该仅对训练集进行,但是测试集上不应该进行这些操作.这样的行操作函数提供了skip = TRUE默认选项,就是要求在predict()时忽略行操作预处理步骤.要特别注意的是,fit()函数不会忽略这样的步骤.
TODO:
如下的行操作函数,仅对训练集有效:
- step_adasyn(): Apply Adaptive Synthetic Algorithm
- step_bsmote():
- step_downsample():
- step_filter():
- step_naomit():
- step_nearmiss():
- step_rose():
- step_slice():
- step_smote():
- step_smotenc():
- step_tomek():
- step_upsample():
- step_sample():
7.4 recipe的整洁显示
recipe对象可以用tidy()函数整洁地显示,其输出结果可以用kable()函数输出为表格.
ames_rec <-
recipe(
Sale_Price ~
Neighborhood +
Gr_Liv_Area +
Year_Built +
Bldg_Type +
Latitude +
Longitude,
data = ames_train
) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01, id = "nei_other") %>%
step_dummy(all_nominal_predictors()) %>%
step_interact(~ Gr_Liv_Area:starts_with("Bldg_Type_")) %>%
step_ns(Latitude, Longitude, deg_free = 20) # 增加样条项
tidy(ames_rec) %>%
knitr::kable(digits = 2)| number | operation | type | trained | skip | id |
|---|---|---|---|---|---|
| 1 | step | log | FALSE | FALSE | log_LtFAn |
| 2 | step | other | FALSE | FALSE | nei_other |
| 3 | step | dummy | FALSE | FALSE | dummy_tR3IC |
| 4 | step | interact | FALSE | FALSE | interact_Tbvqb |
| 5 | step | ns | FALSE | FALSE | ns_ONvwI |
上表中的id列是自动生成的(也可以在tidy()函数中使用参数id = xxx或number = xxx 手动指定),可以认定为每个recipe步骤的编号.在模型拟合后,可以通过指定预处理步骤的id来提取相应的预处理结果.
lm_workflow <-
workflow() %>%
add_model(lm_model) %>%
add_recipe(ames_rec)
lm_fit <- lm_workflow %>%
fit(ames_train)
# 提取预处理结果-通過指定id的方式
estimated_recipe <-
lm_fit %>%
extract_recipe(estimated = TRUE)
# 仅提取"nei_other"步骤的预处理结果,包括没有合并的类别的列表.
tidy(estimated_recipe, id = "nei_other")# A tibble: 20 × 3
terms retained id
<chr> <chr> <chr>
1 Neighborhood North_Ames nei_other
2 Neighborhood College_Creek nei_other
3 Neighborhood Old_Town nei_other
4 Neighborhood Edwards nei_other
5 Neighborhood Somerset nei_other
6 Neighborhood Northridge_Heights nei_other
7 Neighborhood Gilbert nei_other
8 Neighborhood Sawyer nei_other
9 Neighborhood Northwest_Ames nei_other
10 Neighborhood Sawyer_West nei_other
11 Neighborhood Mitchell nei_other
12 Neighborhood Brookside nei_other
13 Neighborhood Crawford nei_other
14 Neighborhood Iowa_DOT_and_Rail_Road nei_other
15 Neighborhood Timberland nei_other
16 Neighborhood Northridge nei_other
17 Neighborhood Stone_Brook nei_other
18 Neighborhood South_and_West_of_Iowa_State_University nei_other
19 Neighborhood Clear_Creek nei_other
20 Neighborhood Meadow_Village nei_other7.4.1 变量的角色
在公式中出现的变量,基本的角色是因变量(outcome)和自变量(predictor).此外,变量还可以有其他角色.如在ames数据集中,每一行可以有一个地址,这既不是自变量也不是因变量,但可以作为其他变量的附加信息(如用来定位感兴趣的观测).
在recipe中,可以通过XX_role()函数来改变变量的角色,主要包括add_role(), remove_role(), update_role().
ames_rec <-
update_role(
address,
new_role = "street address"
)角色名称可以是任何字符串. 一个数据集变量也可以有多重角色,可以用add_role()在已有角色时额外添加角色.
在数据集中保存非自变量、因变量角色的变量列,好处是在进行行操作、随机抽样操作时,可以同步地对这些列进行相同的操作,如果使用数据集外部的一个变量保存这些信息(如地址),就不能自动跟随这些行操作.
7.5 更多的预处理步骤
recipes提供了上百种预处理方法,具体可参见 tiymodels finds。 同时还可以自定义预处理步骤,具体可参见tidymodles-learn-recipes.